深入理解 Java 序列化
关键词:
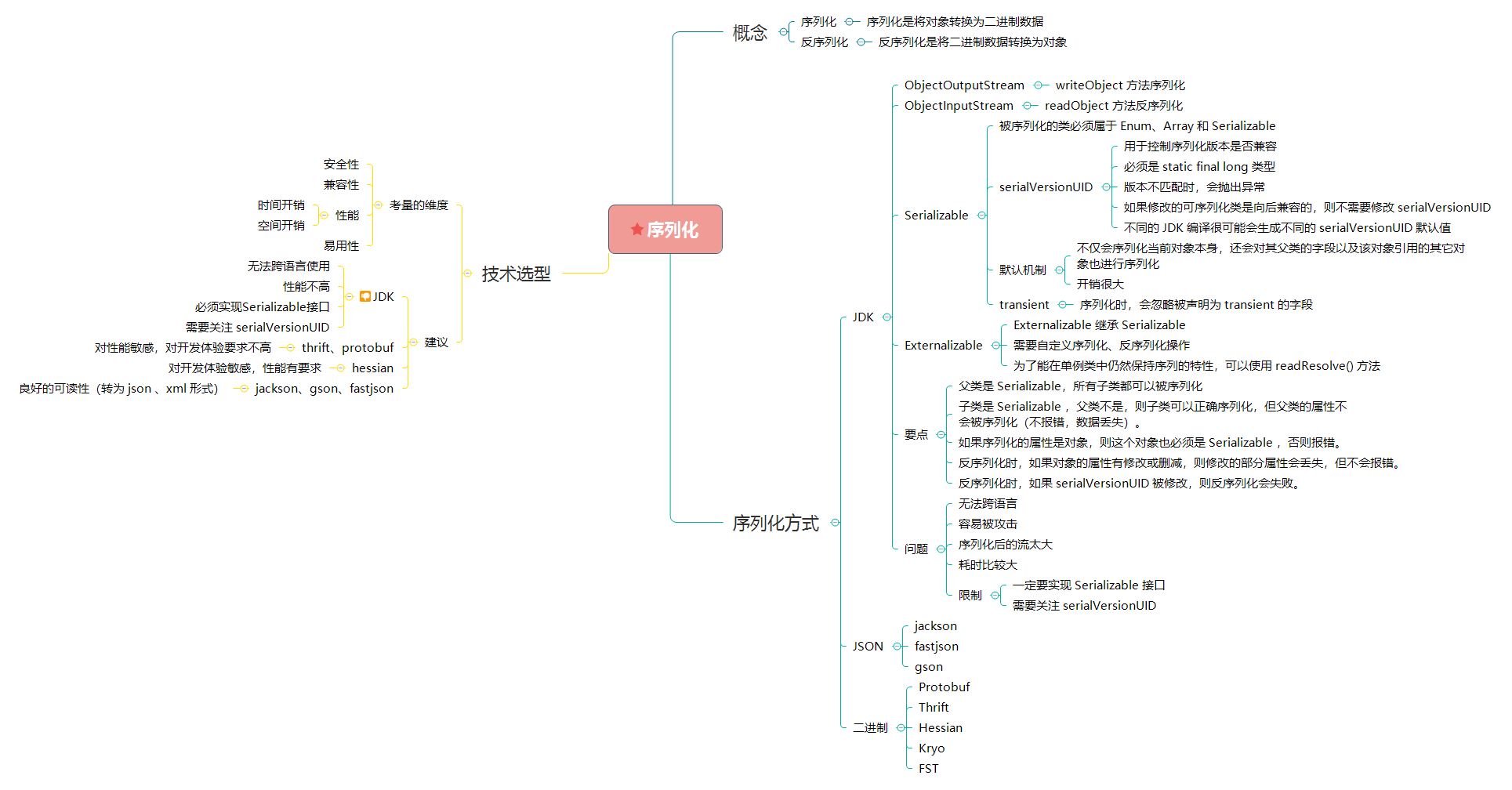
Serializable、serialVersionUID、transient、Externalizable、writeObject、readObject
序列化简介
由于,网络传输的数据必须是二进制数据,但调用方请求的出入参数都是对象。对象是不能直接在网络中传输的,所以需要提前把它转成可传输的二进制,并且要求转换算法是可逆的。
- 序列化(serialize):序列化是将对象转换为二进制数据。
- 反序列化(deserialize):反序列化是将二进制数据转换为对象。

序列化用途
- 序列化可以将对象的字节序列持久化——保存在内存、文件、数据库中。
- 在网络上传送对象的字节序列。
- RMI(远程方法调用)
JDK 序列化
JDK 中内置了一种序列化方式。
ObjectInputStream 和 ObjectOutputStream
Java 通过对象输入输出流来实现序列化和反序列化:
java.io.ObjectOutputStream类的writeObject()方法可以实现序列化;java.io.ObjectInputStream类的readObject()方法用于实现反序列化。
序列化和反序列化示例:
1 | public class SerializeDemo01 { |
JDK 的序列化过程是怎样完成的呢?

图来自 RPC 实战与核心原理 - 序列化
序列化过程就是在读取对象数据的时候,不断加入一些特殊分隔符,这些特殊分隔符用于在反序列化过程中截断用,这就像是文章中的标点符号被用于断句一样。
- 头部数据用来声明序列化协议、序列化版本,用于高低版本向后兼容。
- 对象数据主要包括类名、签名、属性名、属性类型及属性值,当然还有开头结尾等数据,除了属性值属于真正的对象值,其他都是为了反序列化用的元数据。
- 存在对象引用、继承的情况下,就是递归遍历“写对象”逻辑。
🔔 注意:使用 Java 对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的”状态”,即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
Serializable 接口
被序列化的类必须属于 Enum、Array 和 Serializable 类型其中的任何一种,否则将抛出 NotSerializableException 异常。这是因为:在序列化操作过程中会对类型进行检查,如果不满足序列化类型要求,就会抛出异常。
【示例】NotSerializableException 错误
1 | public class UnSerializeDemo { |
输出:结果就是出现如下异常信息。
1 | Exception in thread "main" java.io.NotSerializableException: |
serialVersionUID
请注意 serialVersionUID 字段,你可以在 Java 世界的无数类中看到这个字段。
serialVersionUID 有什么作用,如何使用 serialVersionUID?
serialVersionUID 是 Java 为每个序列化类产生的版本标识。它可以用来保证在反序列时,发送方发送的和接受方接收的是可兼容的对象。如果接收方接收的类的 serialVersionUID 与发送方发送的 serialVersionUID 不一致,会抛出 InvalidClassException。
如果可序列化类没有显式声明 serialVersionUID,则序列化运行时将基于该类的各个方面计算该类的默认 serialVersionUID 值。尽管这样,还是建议在每一个序列化的类中显式指定 serialVersionUID 的值。因为不同的 jdk 编译很可能会生成不同的 serialVersionUID 默认值,从而导致在反序列化时抛出 InvalidClassExceptions 异常。
serialVersionUID 字段必须是 static final long 类型。
我们来举个例子:
(1)有一个可序列化类 Person
1 | public class Person implements Serializable { |
(2)开发过程中,对 Person 做了修改,增加了一个字段 email,如下:
1 | public class Person implements Serializable { |
由于这个类和老版本不兼容,我们需要修改版本号:
1 | private static final long serialVersionUID = 2L; |
再次进行反序列化,则会抛出 InvalidClassException 异常。
综上所述,我们大概可以清楚:**serialVersionUID 用于控制序列化版本是否兼容**。若我们认为修改的可序列化类是向后兼容的,则不修改 serialVersionUID。
默认序列化机制
如果仅仅只是让某个类实现 Serializable 接口,而没有其它任何处理的话,那么就会使用默认序列化机制。
使用默认机制,在序列化对象时,不仅会序列化当前对象本身,还会对其父类的字段以及该对象引用的其它对象也进行序列化。同样地,这些其它对象引用的另外对象也将被序列化,以此类推。所以,如果一个对象包含的成员变量是容器类对象,而这些容器所含有的元素也是容器类对象,那么这个序列化的过程就会较复杂,开销也较大。
🔔 注意:这里的父类和引用对象既然要进行序列化,那么它们当然也要满足序列化要求:被序列化的类必须属于 Enum、Array 和 Serializable 类型其中的任何一种。
JDK 序列化要点
Java 的序列化能保证对象状态的持久保存,但是遇到一些对象结构复杂的情况还是难以处理,这里归纳一下:
- 父类是
Serializable,所有子类都可以被序列化。 - 子类是
Serializable,父类不是,则子类可以正确序列化,但父类的属性不会被序列化(不报错,数据丢失)。 - 如果序列化的属性是对象,则这个对象也必须是
Serializable,否则报错。 - 反序列化时,如果对象的属性有修改或删减,则修改的部分属性会丢失,但不会报错。
- 反序列化时,如果
serialVersionUID被修改,则反序列化会失败。
transient
在现实应用中,有些时候不能使用默认序列化机制。比如,希望在序列化过程中忽略掉敏感数据,或者简化序列化过程。下面将介绍若干影响序列化的方法。
序列化时,默认序列化机制会忽略被声明为 transient 的字段,该字段的内容在序列化后无法访问。
我们将 SerializeDemo01 示例中的内部类 Person 的 age 字段声明为 transient,如下所示:
1 | public class SerializeDemo02 { |
从输出结果可以看出,age 字段没有被序列化。
Externalizable 接口
无论是使用 transient 关键字,还是使用 writeObject() 和 readObject() 方法,其实都是基于 Serializable 接口的序列化。
JDK 中提供了另一个序列化接口–Externalizable。
可序列化类实现 Externalizable 接口之后,基于 Serializable 接口的默认序列化机制就会失效。
我们来基于 SerializeDemo02 再次做一些改动,代码如下:
1 | public class ExternalizeDemo01 { |
从该结果,一方面可以看出 Person 对象中任何一个字段都没有被序列化。另一方面,如果细心的话,还可以发现这此次序列化过程调用了 Person 类的无参构造方法。
Externalizable继承于Serializable,它增添了两个方法:writeExternal()与readExternal()。这两个方法在序列化和反序列化过程中会被自动调用,以便执行一些特殊操作。当使用该接口时,序列化的细节需要由程序员去完成。如上所示的代码,由于writeExternal()与readExternal()方法未作任何处理,那么该序列化行为将不会保存/读取任何一个字段。这也就是为什么输出结果中所有字段的值均为空。- 另外,若使用
Externalizable进行序列化,当读取对象时,会调用被序列化类的无参构造方法去创建一个新的对象;然后再将被保存对象的字段的值分别填充到新对象中。这就是为什么在此次序列化过程中 Person 类的无参构造方法会被调用。由于这个原因,实现Externalizable接口的类必须要提供一个无参的构造方法,且它的访问权限为public。
对上述 Person 类作进一步的修改,使其能够对 name 与 age 字段进行序列化,但要忽略掉 gender 字段,如下代码所示:
1 | public class ExternalizeDemo02 { |
Externalizable 接口的替代方法
实现 Externalizable 接口可以控制序列化和反序列化的细节。它有一个替代方法:实现 Serializable 接口,并添加 writeObject(ObjectOutputStream out) 与 readObject(ObjectInputStream in) 方法。序列化和反序列化过程中会自动回调这两个方法。
示例如下所示:
1 | public class SerializeDemo03 { |
在 writeObject() 方法中会先调用 ObjectOutputStream 中的 defaultWriteObject() 方法,该方法会执行默认的序列化机制,如上节所述,此时会忽略掉 age 字段。然后再调用 writeInt() 方法显示地将 age 字段写入到 ObjectOutputStream 中。readObject() 的作用则是针对对象的读取,其原理与 writeObject() 方法相同。
🔔 注意:
writeObject()与readObject()都是private方法,那么它们是如何被调用的呢?毫无疑问,是使用反射。详情可见ObjectOutputStream中的writeSerialData方法,以及ObjectInputStream中的readSerialData方法。
readResolve() 方法
当我们使用 Singleton 模式时,应该是期望某个类的实例应该是唯一的,但如果该类是可序列化的,那么情况可能会略有不同。此时对第 2 节使用的 Person 类进行修改,使其实现 Singleton 模式,如下所示:
1 | public class SerializeDemo04 { |
值得注意的是,从文件中获取的 Person 对象与 Person 类中的单例对象并不相等。为了能在单例类中仍然保持序列的特性,可以使用 readResolve() 方法。在该方法中直接返回 Person 的单例对象。我们在 SerializeDemo04 示例的基础上添加一个 readResolve 方法, 如下所示:
1 | public class SerializeDemo05 { |
JDK 序列化的问题
- 无法跨语言:JDK 序列化目前只适用基于 Java 语言实现的框架,其它语言大部分都没有使用 Java 的序列化框架,也没有实现 JDK 序列化这套协议。因此,如果是两个基于不同语言编写的应用程序相互通信,则无法实现两个应用服务之间传输对象的序列化与反序列化。
- 容易被攻击:对象是通过在
ObjectInputStream上调用readObject()方法进行反序列化的,它可以将类路径上几乎所有实现了Serializable接口的对象都实例化。这意味着,在反序列化字节流的过程中,该方法可以执行任意类型的代码,这是非常危险的。对于需要长时间进行反序列化的对象,不需要执行任何代码,也可以发起一次攻击。攻击者可以创建循环对象链,然后将序列化后的对象传输到程序中反序列化,这种情况会导致hashCode方法被调用次数呈次方爆发式增长, 从而引发栈溢出异常。例如下面这个案例就可以很好地说明。 - 序列化后的流太大:JDK 序列化中使用了
ObjectOutputStream来实现对象转二进制编码,编码后的数组很大,非常影响存储和传输效率。 - 序列化性能太差:Java 的序列化耗时比较大。序列化的速度也是体现序列化性能的重要指标,如果序列化的速度慢,就会影响网络通信的效率,从而增加系统的响应时间。
- 序列化编程限制:
- JDK 序列化一定要实现
Serializable接口。 - JDK 序列化**需要关注
serialVersionUID**。
- JDK 序列化一定要实现
二进制序列化
上节详细介绍了 JDK 序列化方式,由于其性能不高,且存在很多其他问题,所以业界有了很多其他优秀的二进制序列化库。
Protobuf
Protobuf 是 Google 公司内部的混合语言数据标准,是一种轻便、高效的结构化数据存储格式,可以用于结构化数据序列化,支持 Java、Python、C++、Go 等语言。Protobuf 使用的时候需要定义 IDL(Interface description language),然后使用不同语言的 IDL
编译器,生成序列化工具类。
优点:
- 序列化后体积相比 JSON、Hessian 小很多
- 序列化反序列化速度很快,不需要通过反射获取类型
- 语言和平台无关(基于 IDL),IDL 能清晰地描述语义,所以足以帮助并保证应用程序之间的类型不会丢失,无需类似 XML 解析器
- 消息格式升级和兼容性不错,可以做到后向兼容
- 支持 Java, C++, Python 三种语言
缺点:
- Protobuf 对于具有反射和动态能力的语言来说,用起来很费劲。
Thrift
Thrift 是 apache 开源项目,是一个点对点的 RPC 实现。
它具有以下特性:
- 支持多种语言(目前支持 28 种语言,如:C++、go、Java、Php、Python、Ruby 等等)。
- 使用了组建大型数据交换及存储工具,对于大型系统中的内部数据传输,相对于 Json 和 xml 在性能上和传输大小上都有明显的优势。
- 支持三种比较典型的编码方式(通用二进制编码,压缩二进制编码,优化的可选字段压缩编解码)。
Hessian
Hessian 是动态类型、二进制、紧凑的,并且可跨语言移植的一种序列化框架。Hessian 协议要比 JDK、JSON 更加紧凑,性能上要比 JDK、JSON 序列化高效很多,而且生成的字节数也更小。
RPC 框架 Dubbo 就支持 Thrift 和 Hession。
它具有以下特性:
- 支持多种语言。如:Java、Python、C++、C#、PHP、Ruby 等。
- 相对其他二进制序列化库较慢。
Hessian 本身也有问题,官方版本对 Java 里面一些常见对象的类型不支持:
- Linked 系列,LinkedHashMap、LinkedHashSet 等,但是可以通过扩展 CollectionDeserializer 类修复;
- Locale 类,可以通过扩展 ContextSerializerFactory 类修复;
- Byte/Short 反序列化的时候变成 Integer。
Kryo
Kryo 是用于 Java 的快速高效的二进制对象图序列化框架。Kryo 还可以执行自动的深拷贝和浅拷贝。 这是从对象到对象的直接复制,而不是从对象到字节的复制。
它具有以下特性:
- 速度快,序列化体积小
- 官方不支持 Java 以外的其他语言
FST
FST 是一个 Java 实现二进制序列化库。
它具有以下特性:
- 近乎于 100% 兼容 JDK 序列化,且比 JDK 原序列化方式快 10 倍
- 2.17 开始与 Android 兼容
- (可选)2.29 开始支持将任何可序列化的对象图编码/解码为 JSON(包括共享引用)
JSON 序列化
除了二进制序列化方式,还可以选择 JSON 序列化。它的性能比二进制序列化方式差,但是可读性非常好,且广泛应用于 Web 领域。
JSON 是什么
JSON 起源于 1999 年的 JS 语言规范 ECMA262 的一个子集(即 15.12 章节描述了格式与解析),后来 2003 年作为一个数据格式ECMA404(很囧的序号有不有?)发布。
2006 年,作为 rfc4627 发布,这时规范增加到 18 页,去掉没用的部分,十页不到。
JSON 的应用很广泛,这里有超过 100 种语言下的 JSON 库:json.org。
更多的可以参考这里,关于 json 的一切。
JSON 标准
这估计是最简单标准规范之一:
- 只有两种结构:对象内的键值对集合结构和数组,对象用
{}表示、内部是"key":"value",数组用[]表示,不同值用逗号分开 - 基本数值有 7 个:
false/null/true/object/array/number/string - 再加上结构可以嵌套,进而可以用来表达复杂的数据
- 一个简单实例:
1 | { |
扩展阅读:
http://www.json.org/json-zh.html - 图文并茂介绍 json 数据形式
JSON 优缺点
JSON 优点
- 基于纯文本,所以对于人类阅读是很友好的。
- 规范简单,所以容易处理,开箱即用,特别是 JS 类的 ECMA 脚本里是内建支持的,可以直接作为对象使用。
- 平台无关性,因为类型和结构都是平台无关的,而且好处理,容易实现不同语言的处理类库,可以作为多个不同异构系统之间的数据传输格式协议,特别是在 HTTP/REST 下的数据格式。
JSON 缺点
- 性能一般,文本表示的数据一般来说比二进制大得多,在数据传输上和解析处理上都要更影响性能。
- 缺乏 schema,跟同是文本数据格式的 XML 比,在类型的严格性和丰富性上要差很多。XML 可以借由 XSD 或 DTD 来定义复杂的格式,并由此来验证 XML 文档是否符合格式要求,甚至进一步的,可以基于 XSD 来生成具体语言的操作代码,例如 apache xmlbeans。并且这些工具组合到一起,形成一套庞大的生态,例如基于 XML 可以实现 SOAP 和 WSDL,一系列的 ws-*规范。但是我们也可以看到 JSON 在缺乏规范的情况下,实际上有更大一些的灵活性,特别是近年来 REST 的快速发展,已经有一些 schema 相关的发展(例如理解 JSON Schema,使用 JSON Schema, 在线 schema 测试),也有类似于 WSDL 的WADL出现。
JSON 库
Java 中比较流行的 JSON 库有:
- Fastjson - 阿里巴巴开发的 JSON 库,性能十分优秀。
- Jackson - 社区十分活跃且更新速度很快。Spring 框架默认 JSON 库。
- Gson - 谷歌开发的 JSON 库,目前功能最全的 JSON 库 。
从性能上来看,一般情况下:Fastjson > Jackson > Gson
JSON 编码指南
遵循好的设计与编码风格,能提前解决 80%的问题,个人推荐 Google JSON 风格指南。
简单摘录如下:
- 属性名和值都是用双引号,不要把注释写到对象里面,对象数据要简洁
- 不要随意结构化分组对象,推荐是用扁平化方式,层次不要太复杂
- 命名方式要有意义,比如单复数表示
- 驼峰式命名,遵循 Bean 规范
- 使用版本来控制变更冲突
- 对于一些关键字,不要拿来做 key
- 如果一个属性是可选的或者包含空值或 null 值,考虑从 JSON 中去掉该属性,除非它的存在有很强的语义原因
- 序列化枚举类型时,使用 name 而不是 value
- 日期要用标准格式处理
- 设计好通用的分页参数
- 设计好异常处理
JSON API与 Google JSON 风格指南有很多可以相互参照之处。
JSON API是数据交互规范,用以定义客户端如何获取与修改资源,以及服务器如何响应对应请求。
JSON API 设计用来最小化请求的数量,以及客户端与服务器间传输的数据量。在高效实现的同时,无需牺牲可读性、灵活性和可发现性。
序列化技术选型
市面上有如此多的序列化技术,那么我们在应用时如何选择呢?
序列化技术选型,需要考量的维度,根据重要性从高到低,依次有:
- 安全性:是否存在漏洞。如果存在漏洞,就有被攻击的可能性。
- 兼容性:版本升级后的兼容性是否很好,是否支持更多的对象类型,是否是跨平台、跨语言的。服务调用的稳定性与可靠性,要比服务的性能更加重要。
- 性能
- 时间开销:序列化、反序列化的耗时性能自然越小越好。
- 空间开销:序列化后的数据越小越好,这样网络传输效率就高。
- 易用性:类库是否轻量化,API 是否简单易懂。
鉴于以上的考量,序列化技术的选型建议如下:
- JDK 序列化:性能较差,且有很多使用限制,不建议使用。
- Thrift、Protobuf:适用于对性能敏感,对开发体验要求不高。
- Hessian:适用于对开发体验敏感,性能有要求。
- Jackson、Gson、Fastjson:适用于对序列化后的数据要求有良好的可读性(转为 json 、xml 形式)。

