JVM 实战
JVM 调优概述
GC 性能指标
对于 JVM 调优来说,需要先明确调优的目标。
从性能的角度看,通常关注三个指标:
吞吐量(throughput)- 指不考虑 GC 引起的停顿时间或内存消耗,垃圾收集器能支撑应用达到的最高性能指标。停顿时间(latency)- 其度量标准是缩短由于垃圾啊收集引起的停顿时间或者完全消除因垃圾收集所引起的停顿,避免应用运行时发生抖动。垃圾回收频率- 久发生一次指垃圾回收呢?通常垃圾回收的频率越低越好,增大堆内存空间可以有效降低垃圾回收发生的频率,但同时也意味着堆积的回收对象越多,最终也会增加回收时的停顿时间。所以我们只要适当地增大堆内存空间,保证正常的垃圾回收频率即可。
大多数情况下调优会侧重于其中一个或者两个方面的目标,很少有情况可以兼顾三个不同的角度。
调优原则
GC 优化的两个目标:
- 降低 Full GC 的频率
- 减少 Full GC 的执行时间
GC 优化的基本原则是:将不同的 GC 参数应用到两个及以上的服务器上然后比较它们的性能,然后将那些被证明可以提高性能或减少 GC 执行时间的参数应用于最终的工作服务器上。
降低 Minor GC 频率
如果新生代空间较小,Eden 区很快被填满,就会导致频繁 Minor GC,因此我们可以通过增大新生代空间来降低 Minor GC 的频率。
可能你会有这样的疑问,扩容 Eden 区虽然可以减少 Minor GC 的次数,但不会增加单次 Minor GC 的时间吗?如果单次 Minor GC 的时间增加,那也很难达到我们期待的优化效果呀。
我们知道,单次 Minor GC 时间是由两部分组成:T1(扫描新生代)和 T2(复制存活对象)。假设一个对象在 Eden 区的存活时间为 500ms,Minor GC 的时间间隔是 300ms,那么正常情况下,Minor GC 的时间为 :T1+T2。
当我们增大新生代空间,Minor GC 的时间间隔可能会扩大到 600ms,此时一个存活 500ms 的对象就会在 Eden 区中被回收掉,此时就不存在复制存活对象了,所以再发生 Minor GC 的时间为:两次扫描新生代,即 2T1。
可见,扩容后,Minor GC 时增加了 T1,但省去了 T2 的时间。通常在虚拟机中,复制对象的成本要远高于扫描成本。
如果在堆内存中存在较多的长期存活的对象,此时增加年轻代空间,反而会增加 Minor GC 的时间。如果堆中的短期对象很多,那么扩容新生代,单次 Minor GC 时间不会显著增加。因此,单次 Minor GC 时间更多取决于 GC 后存活对象的数量,而非 Eden 区的大小。
降低 Full GC 的频率
Full GC 相对来说会比 Minor GC 更耗时。减少进入老年代的对象数量可以显著降低 Full GC 的频率。
减少创建大对象:如果对象占用内存过大,在 Eden 区被创建后会直接被传入老年代。在平常的业务场景中,我们习惯一次性从数据库中查询出一个大对象用于 web 端显示。例如,我之前碰到过一个一次性查询出 60 个字段的业务操作,这种大对象如果超过年轻代最大对象阈值,会被直接创建在老年代;即使被创建在了年轻代,由于年轻代的内存空间有限,通过 Minor GC 之后也会进入到老年代。这种大对象很容易产生较多的 Full GC。
我们可以将这种大对象拆解出来,首次只查询一些比较重要的字段,如果还需要其它字段辅助查看,再通过第二次查询显示剩余的字段。
增大堆内存空间:在堆内存不足的情况下,增大堆内存空间,且设置初始化堆内存为最大堆内存,也可以降低 Full GC 的频率。
降低 Full GC 的时间
Full GC 的执行时间比 Minor GC 要长很多,因此,如果在 Full GC 上花费过多的时间(超过 1s),将可能出现超时错误。
- 如果通过减小老年代内存来减少 Full GC 时间,可能会引起
OutOfMemoryError或者导致 Full GC 的频率升高。 - 另外,如果通过增加老年代内存来降低 Full GC 的频率,Full GC 的时间可能因此增加。
因此,你需要把老年代的大小设置成一个“合适”的值。
GC 优化需要考虑的 JVM 参数
| 类型 | 参数 | 描述 |
|---|---|---|
| 堆内存大小 | -Xms |
启动 JVM 时堆内存的大小 |
-Xmx |
堆内存最大限制 | |
| 新生代空间大小 | -XX:NewRatio |
新生代和老年代的内存比 |
-XX:NewSize |
新生代内存大小 | |
-XX:SurvivorRatio |
Eden 区和 Survivor 区的内存比 |
GC 优化时最常用的参数是-Xms,-Xmx和-XX:NewRatio。-Xms和-Xmx参数通常是必须的,所以NewRatio的值将对 GC 性能产生重要的影响。
有些人可能会问如何设置永久代内存大小,你可以用-XX:PermSize和-XX:MaxPermSize参数来进行设置,但是要记住,只有当出现OutOfMemoryError错误时你才需要去设置永久代内存。
GC 优化的过程
GC 优化的过程大致可分为以下步骤:
(1)监控 GC 状态
你需要监控 GC 从而检查系统中运行的 GC 的各种状态。
(2)分析 GC 日志
在检查 GC 状态后,你需要分析监控结构并决定是否需要进行 GC 优化。如果分析结果显示运行 GC 的时间只有 0.1-0.3 秒,那么就不需要把时间浪费在 GC 优化上,但如果运行 GC 的时间达到 1-3 秒,甚至大于 10 秒,那么 GC 优化将是很有必要的。
但是,如果你已经分配了大约 10GB 内存给 Java,并且这些内存无法省下,那么就无法进行 GC 优化了。在进行 GC 优化之前,你需要考虑为什么你需要分配这么大的内存空间,如果你分配了 1GB 或 2GB 大小的内存并且出现了OutOfMemoryError,那你就应该执行堆快照(heap dump)来消除导致异常的原因。
🔔 注意:
堆快照(heap dump)是一个用来检查 Java 内存中的对象和数据的内存文件。该文件可以通过执行 JDK 中的
jmap命令来创建。在创建文件的过程中,所有 Java 程序都将暂停,因此,不要在系统执行过程中创建该文件。
你可以在互联网上搜索 heap dump 的详细说明。
(3)选择合适 GC 回收器
如果你决定要进行 GC 优化,那么你需要选择一个 GC 回收器,并且为它设置合理 JVM 参数。此时如果你有多个服务器,请如上文提到的那样,在每台机器上设置不同的 GC 参数并分析它们的区别。
(4)分析结果
在设置完 GC 参数后就可以开始收集数据,请在收集至少 24 小时后再进行结果分析。如果你足够幸运,你可能会找到系统的最佳 GC 参数。如若不然,你还需要分析输出日志并检查分配的内存,然后需要通过不断调整 GC 类型/内存大小来找到系统的最佳参数。
(5)应用优化配置
如果 GC 优化的结果令人满意,就可以将参数应用到所有服务器上,并停止 GC 优化。
在下面的章节中,你将会看到上述每一步所做的具体工作。
GC 日志
获取 GC 日志
获取 GC 日志有两种方式:
- 使用
jstat命令动态查看 - 在容器中设置相关参数打印 GC 日志
jstat 命令查看 GC
jstat -gc 统计垃圾回收堆的行为:
1 | jstat -gc 1262 |
也可以设置间隔固定时间来打印:
1 | jstat -gc 1262 2000 20 |
这个命令意思就是每隔 2000ms 输出 1262 的 gc 情况,一共输出 20 次
打印 GC 的参数
通过 JVM 参数预先设置 GC 日志,通常有以下几种 JVM 参数设置:
1 | -XX:+PrintGC 输出 GC 日志 |
如果是长时间的 GC 日志,我们很难通过文本形式去查看整体的 GC 性能。此时,我们可以通过GCView工具打开日志文件,图形化界面查看整体的 GC 性能。
【示例】Tomcat 设置示例
1 | JAVA_OPTS="-server -Xms2000m -Xmx2000m -Xmn800m -XX:PermSize=64m -XX:MaxPermSize=256m -XX:SurvivorRatio=4 |
-Xms2000m -Xmx2000m -Xmn800m -XX:PermSize=64m -XX:MaxPermSize=256m
Xms,即为 jvm 启动时得 JVM 初始堆大小,Xmx 为 jvm 的最大堆大小,xmn 为新生代的大小,permsize 为永久代的初始大小,MaxPermSize 为永久代的最大空间。-XX:SurvivorRatio=4
SurvivorRatio 为新生代空间中的 Eden 区和救助空间 Survivor 区的大小比值,默认是 8,则两个 Survivor 区与一个 Eden 区的比值为 2:8,一个 Survivor 区占整个年轻代的 1/10。调小这个参数将增大 survivor 区,让对象尽量在 survitor 区呆长一点,减少进入年老代的对象。去掉救助空间的想法是让大部分不能马上回收的数据尽快进入年老代,加快年老代的回收频率,减少年老代暴涨的可能性,这个是通过将-XX:SurvivorRatio 设置成比较大的值(比如 65536)来做到。-verbose:gc -Xloggc:$CATALINA_HOME/logs/gc.log
将虚拟机每次垃圾回收的信息写到日志文件中,文件名由 file 指定,文件格式是平文件,内容和-verbose:gc 输出内容相同。-Djava.awt.headless=trueHeadless 模式是系统的一种配置模式。在该模式下,系统缺少了显示设备、键盘或鼠标。-XX:+PrintGCTimeStamps -XX:+PrintGCDetails
设置 gc 日志的格式-Dsun.rmi.dgc.server.gcInterval=600000 -Dsun.rmi.dgc.client.gcInterval=600000
指定 rmi 调用时 gc 的时间间隔-XX:+UseConcMarkSweepGC -XX:MaxTenuringThreshold=15采用并发 gc 方式,经过 15 次 minor gc 后进入年老代
分析 GC 日志
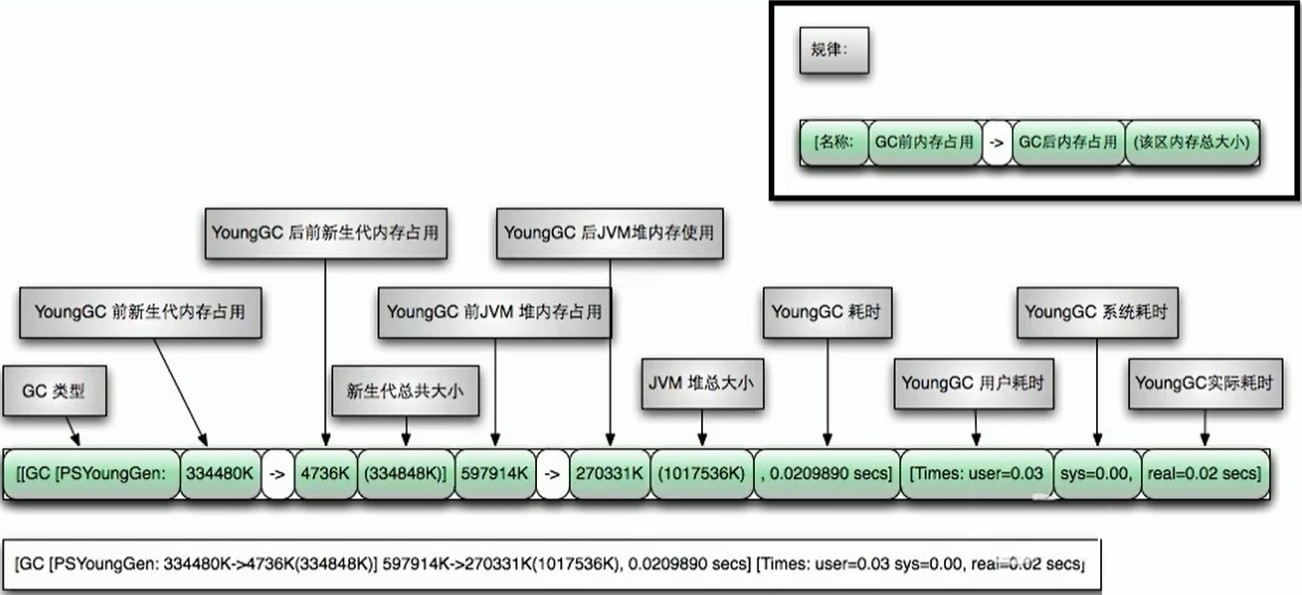
Young GC 回收日志:
1 | 2016-07-05T10:43:18.093+0800: 25.395: [GC [PSYoungGen: 274931K->10738K(274944K)] 371093K->147186K(450048K), 0.0668480 secs] [Times: user=0.17 sys=0.08, real=0.07 secs] |
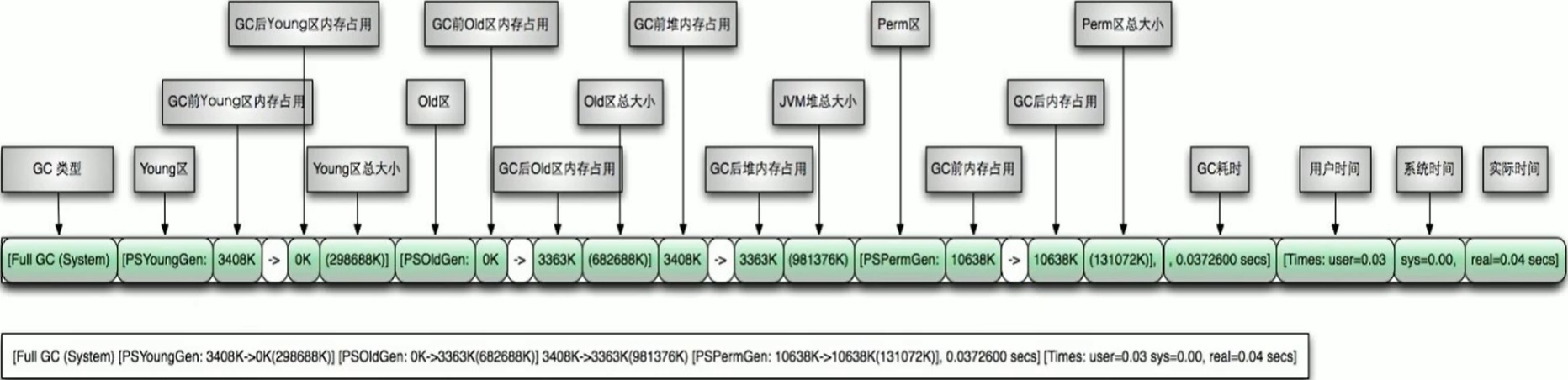
Full GC 回收日志:
1 | 2016-07-05T10:43:18.160+0800: 25.462: [Full GC [PSYoungGen: 10738K->0K(274944K)] [ParOldGen: 136447K->140379K(302592K)] 147186K->140379K(577536K) [PSPermGen: 85411K->85376K(171008K)], 0.6763541 secs] [Times: user=1.75 sys=0.02, real=0.68 secs] |
通过上面日志分析得出,PSYoungGen、ParOldGen、PSPermGen 属于 Parallel 收集器。其中 PSYoungGen 表示 gc 回收前后年轻代的内存变化;ParOldGen 表示 gc 回收前后老年代的内存变化;PSPermGen 表示 gc 回收前后永久区的内存变化。young gc 主要是针对年轻代进行内存回收比较频繁,耗时短;full gc 会对整个堆内存进行回城,耗时长,因此一般尽量减少 full gc 的次数
通过两张图非常明显看出 gc 日志构成:
YOUNG GC
FULL GC
CPU 过高
定位步骤:
(1)执行 top -c 命令,找到 cpu 最高的进程的 id
(2)jstack PID 导出 Java 应用程序的线程堆栈信息。
示例:
1 | jstack 6795 |
在打印的堆栈日志文件中,tid 和 nid 的含义:
1 | nid : 对应的 Linux 操作系统下的 tid 线程号,也就是前面转化的 16 进制数字 |
在 CPU 过高的情况下,查找响应的线程,一般定位都是用 nid 来定位的。而如果发生死锁之类的问题,一般用 tid 来定位。
(3)定位 CPU 高的线程打印其 nid
查看线程下具体进程信息的命令如下:
top -H -p 6735
1 | top - 14:20:09 up 611 days, 2:56, 1 user, load average: 13.19, 7.76, 7.82 |
由此可以看出占用 CPU 较高的线程,但是这些还不高,无法直接定位到具体的类。nid 是 16 进制的,所以我们要获取线程的 16 进制 ID:
1 | printf "%x\n" 6800 |
1 | 输出结果:45cd |
然后根据输出结果到 jstack 打印的堆栈日志中查定位:
1 | "catalina-exec-5692" daemon prio=10 tid=0x00007f3b05013800 nid=0x45cd waiting on condition [0x00007f3ae08e3000] |
GC 配置
详细参数说明请参考官方文档:JavaHotSpot VM Options,这里仅列举常用参数。
堆大小设置
年轻代的设置很关键。
JVM 中最大堆大小有三方面限制:
- 相关操作系统的数据模型(32-bt 还是 64-bit)限制;
- 系统的可用虚拟内存限制;
- 系统的可用物理内存限制。
1 | 整个堆大小 = 年轻代大小 + 年老代大小 + 持久代大小 |
- 持久代一般固定大小为
64m。使用-XX:PermSize设置。 - 官方推荐年轻代占整个堆的 3/8。使用
-Xmn设置。
JVM 内存配置
| 配置 | 描述 |
|---|---|
-Xss |
虚拟机栈大小。 |
-Xms |
堆空间初始值。 |
-Xmx |
堆空间最大值。 |
-Xmn |
新生代空间大小。 |
-XX:NewSize |
新生代空间初始值。 |
-XX:MaxNewSize |
新生代空间最大值。 |
-XX:NewRatio |
新生代与年老代的比例。默认为 2,意味着老年代是新生代的 2 倍。 |
-XX:SurvivorRatio |
新生代中调整 eden 区与 survivor 区的比例,默认为 8。即 eden 区为 80% 的大小,两个 survivor 分别为 10% 的大小。 |
-XX:PermSize |
永久代空间的初始值。 |
-XX:MaxPermSize |
永久代空间的最大值。 |
GC 类型配置
| 配置 | 描述 |
|---|---|
-XX:+UseSerialGC |
使用 Serial + Serial Old 垃圾回收器组合 |
-XX:+UseParallelGC |
使用 Parallel Scavenge + Parallel Old 垃圾回收器组合 |
-XX:+UseParallelOldGC |
|
-XX:+UseParNewGC |
使用 ParNew + Serial Old 垃圾回收器 |
-XX:+UseConcMarkSweepGC |
使用 CMS + ParNew + Serial Old 垃圾回收器组合 |
-XX:+UseG1GC |
使用 G1 垃圾回收器 |
-XX:ParallelCMSThreads |
并发标记扫描垃圾回收器 = 为使用的线程数量 |
垃圾回收器通用参数
| 配置 | 描述 |
|---|---|
PretenureSizeThreshold |
晋升年老代的对象大小。默认为 0。比如设为 10M,则超过 10M 的对象将不在 eden 区分配,而直接进入年老代。 |
MaxTenuringThreshold |
晋升老年代的最大年龄。默认为 15。比如设为 10,则对象在 10 次普通 GC 后将会被放入年老代。 |
DisableExplicitGC |
禁用 System.gc() |
JMX
开启 JMX 后,可以使用 jconsole 或 jvisualvm 进行监控 Java 程序的基本信息和运行情况。
1 | -Dcom.sun.management.jmxremote=true |
-Djava.rmi.server.hostname 指定 Java 程序运行的服务器,-Dcom.sun.management.jmxremote.port 指定服务监听端口。
远程 DEBUG
如果开启 Java 应用的远程 Debug 功能,需要指定如下参数:
1 | -Xdebug |
address 即为远程 debug 的监听端口。
HeapDump
1 | -XX:-OmitStackTraceInFastThrow -XX:+HeapDumpOnOutOfMemoryError |
辅助配置
| 配置 | 描述 |
|---|---|
-XX:+PrintGCDetails |
打印 GC 日志 |
-Xloggc:<filename> |
指定 GC 日志文件名 |
-XX:+HeapDumpOnOutOfMemoryError |
内存溢出时输出堆快照文件 |

